Considération Générales
Organisation du repo
La nouvelle infrastructure doit nous permettre de facilement :
- Savoir quel service est installé où
- mettre à jours les machines
- mettre à jours toutes les instances d’un même service
Inventaire
L’inventaire est composé de l’arborescence suivante :
hosts.ini
group_vars/
|-vm1/
|-vars.yml
|-vault.yml
|-vm2/
|-vars.yml
|-vault.yml
host_vars/
|-service1
|-vars.yml
|-vault.yml
|-service2.yml
|-vars.yml
|-vault.yml
Fichiers d’inventaires
Nous avons 3 fichiers d’inventaires :
01-applications.yml: contient la liste de services groupés par type d’applications10-machines.yml: contient la liste des services groupés par VM50-servers.yml: contient la liste des VMs et groupes particulier
l’ajout d’un nouveau service consiste à ajouter CODESERVICE_CLIENT.yml dans les groupes suivants :
- la vm sur lequel il est installé dans le fichier
10-machines.yml - le type de service auquel il appartient dans le fichier
01-applications.yml
ex : ajout du yeswiki du creal qui est sur la machine capucine
# 10-machines.yml
[capucine]
…
yw_creal
# 01 applications.yml
[yeswiki]
…
yw_creal
Fichier group_vars/vmN.yml
Ce fichier contient les variables suivantes :
ansible_host: vmN.yml
ex: pour la vm capucine
ansible_host: capucine
Créer des secrets
chaque host ou groupe possède un dossier à son nom avec ses variable personnelles. Ces dossier comportent 2 fichiers :
- vars pour les variables non chiffrées
- vault poru les variables chiffrées.
Chaque variable devant être chiffrée est présente dans le fichier vars et fait référence à une autre variable (ex : vault_nom_var) présente dans le fichier vault chiffré.
Cette convention permet de conserver la liste de variable librement visible et compréhensible.
Le fichier vault peut être créé avec la commande : ansible_vault encrypt path/to/file et peut être modifié via la commande ansible-vault edit path/to/file
ex : creation de ma_var_secrete pour le groupe capucine
capucine/
|-vars
|-vault
# vars
ma_var_secrete: "{{vault_ma_var_secrete}}"
# vault
$ANSIBLE_VAULT;1.1;AES256
65646364343038336231313862336339353735363261336330653562663436306266333061316139
6461396565356234376165613135613164303535613065330a383964626231306433343164336332
64343332663863306136306331303265343931386230383135643539343562376339323631373865
3831616163643630340a313232353137326131373735613239383436363764353536636463373333
61383430383730666430343937313562313235613662653235616338396235353539313864333466
6365393765623463336634616163343365623636346363336139
Inventaire
Host
Les services
L’inventaire contient l’intégralité de nos services. Chaque service est ainsi considéré comme étant un Host ansible. À ce titre, il contient un certain nombre de variables associées dont à minima :
Les Roles pourront se réferrer à la variable supplémentaire
inventory_hostname qui correspond au nom du host que nous considérons
comme l’id du role.
Les machines virtuelles
L’inventaire contient aussi des host correspondant à des machines virtuelles.
Ceci nous permet d’automatiser leur création et la modification de leur ressources
via ansible. Ceci nous permet aussi d’automatiser leur mise à jour.
Groups
Chaque host doit appartenir à 2 groupes. Le premier groupe correspond au type
d’application (ex: nextcloud, yeswiki…). Le deuxième correspond à la machine
sur lequel il est installé (ex: capucine, onagre…). Le host va ainsi :
- pouvoir être appelé lors d’opérations sur tous les groupes comme la mise à jour de tous les nextcloud
- hériter des variables de chacun des groupes.
Groupes de machine :
Ces groupes possèdent les informations sur la machine d’installation du service. Les variables seront entre autre :
ansible_host: nom de la machine pour y accéder en ssh
trusted_proxy: adresse ip du proxy devant la machine
Groupes de service :
Ces groupes peuvent posséder des variables relatives aux application et permettent d’appeler un même role pour l’ensemble des instances d’un service. Exemple de variables :
application_version: la version à utiliser du logiciel
Organisation de l’inventaire
Ansible peut charger plusieurs fichiers d’inventaires. Dans notre cas, nous
chargeons tous les fichier ini (sans extension) ou yaml (.yml) présents dans
le dossier hosts. Nous avons organisés les fichiers de la façon suivante :
- 00-ungrouped : fichier
ini. Il est destiné à contenir temporairement unhostavant que celui-ci ne soit affecté à ses groupes - 01-applications : fichier
ini. Liste les différents services par groupe d’application. - 10-machines : fichier
ini. Liste les différents services par machine - 50-servers.yml: fichier
yaml. Liste les différentes machines virtuelles et les serveurs physiques les possédant.
Ajouter une nouvelle instance d’un service
On peut utiliser le script add-instance pour le faire de manière interactive.
Créer un nouveau role
Créer la structure
Nous n’utilisons que les 4 dossiers suivants pour nos roles :
tasks: Les fichiers de tache. On n’utilise le nommain.ymlque s’il n’y a qu’un fichier. On préfère découper les opérations en fichiers avec un nom évocateur. Si c’est un role de service, il devrait avoir à minimas les fichiers suivants :install.yml,upgrade.yml,restore.yml,uninstall.ymldefaults: Les valeurs par défault du rolehandlers: d’éventuels handlerstemplates: d’éventuels templates
# Exemple d'arborescence
├── defaults
├── handlers
│ └── main.yml
├── README.md
├── tasks
│ └── install.yml
│ └── upgrade.yml
│ └── restore.yml
│ └── uninstall.yml
└── templates
Tester le rôle
Il faut ajouter un hôte <role>_test et le référencer dans :
- Le groupe de sa machine (
bardane), dans10-machines; - Le groupe de son service (
<role>), dans01-applications
bardane, la VM de test, a une entrée DNS en *.test.paquerette.eu : on utilisera ce parent pour la variable application_domain.
Pour tester le rôle, on créera un playbook install/<role> qui importe le rôle.
Par sécurité, on se limitera explicitement à l’hôte test. Exemple pour coturn :
ansible-playbook playbook/install/<role>.yml --limit coturn_test
Passer en production
Créer un nouvel hôte, comme pour l’hôte de test, et penser à renseigner les mêmes variables (secrets, domaine…)
⚠️ Penser à ajouter le domaine dans la zone DNS.
Ajouter ensuite une entrée dans la documentation pour indiquer comment utiliser le service, en plus d’une entrée pour indiquer comment configurer le service.
Ajouter le role dans la doc
Éditer le fichier SUMMARY.md et ajouter le role dans la bonne section.
Bonne pratiques
Les chemins par défaut
Autant que possible, une application doit suivre les directives suivantes :
- S’installer dans :
/var/www/APPLICATION_ID, avec configuration et petites données - Mettre les données volumineuses dans :
/mnt/nextcloud/APPLICATION_ID - tourner avec l’utilisateur :
APPLICATION_ID - exposer ses logs dans :
/var/log/nextcloud/APPLICATION_ID.log
De même en utilisant les roles existant, elle aura :
- un pool php_fpm portant le nom :
APPLICATION_ID - un fichier conf nginx :
/etc/nginx/conf.d/APPLICATION_ID.conf - une BDD du nom
APPLICATION_ID_dbavec l’utilisateurAPPLICATION_ID_usr - un fichier de backup :
/etc/rustic/APPLICATION_ID.toml
Et d’une manière générale utiliser au maximum l’id de l’application comme référence pour le role afin de ne pas multiplier le variables.
{{ application_id }}vaut par défaut{{ inventory_hostname }}.
Exposition sur le web
L’URL est définie au niveau de l’hôte dans la variable application_domain.
Par défaut on suppose que l’application répond directement aux requêtes. Idéalement, le rôle prend en compte la possible existance de la variable behind_reverse_proxy (à true), qui indique que l’application est derrière un reverse proxy.
Exposition directe (sans reverse proxy)
Si l’application prend en charge TLS, on générera les certificats nécessaires avec la tâche :
- name: Register Let's Encrypt certificate
import_role:
name: certbot
tasks_from: cert.yml
Il y a deux cas.
- Si le service est non-HTTPS (TCP) ou bien chiffre lui-même la connexion, appeler le rôle avec la variable
certbot_install_nginx: true. - Si le service est exposé derrière le
nginxde la machine, il faut copier un fichier de configuration dans/etc/nginx/conf.d.
Les certificats sont déposés dans /etc/letsencrypt/live/{{ application_domain }}. La clé publique s’appelle fullchain.pem et la clé privée privkey.pem. Le renouvellement est automatique.
ℹ️ Dans le cas d’un service non-HTTP(S), il faudra probablement modifier la configuration réseau de la machine cible.
Cas du reverse proxy
Prendre soin de désactiver TLS, la terminaison étant assurée par le reverse proxy.
Backups
#todo ajouter password au niveau des hosts_vars du service
Les backups sont assurés par rustic. Un rôle gère déjà la configuration, la planfication et l’externalisation des backups.
Il faut au minimum définir la variable suivante :
rustic_backup_sources: répertoires ou fichiers à sauvegarder, séparés par des virgules
Si l’application a besoin d’un backup logique de base de données :
application_type:localoudockerdb_type: SGBD :postgresqloumariadbsupportés ;application_db_name: nom de la DB (si locale) ou du conteneur.
Le comportement générique du backup peut être étendu avec les variables suivantes :
rustic_backup_before: script à lancer avant le backup ;rustic_backup_after: script à lancer après le backup.
Enfin, importer le fichier de tâches qui s’occupe de l’initialisation :
- name: Configure backup
import_role:
name: rustic
tasks_from: add_backup.yml
tags:
- rustic
Télécharger des fichiers
Dans le cas d’un ou des fichier(s) qui seraient téléchargés sur différentes machines (e.g. un role voué à s’exécuter sur un groupe), utiliser le rôle download_archive pour gérer sa mise en cache.
Créer une nouvelle VM
Pour le reste de ce document, on suppose que la VM que l’on veut créer s’appelle bleuet.
Inventaire
Hôte
On commence par créer un dossier bleuet_vm dans host_vars. Le fichier vars.yml contient :
# Derniers chiffres de l'IP désirée
ip = XX
# Mot de passe de l'utilisateur paquerette
vm_admin_password = {{ vault_vm_admin_password }}
L’IP est choisie sur l’hyperviseur en connaissance des autres IP existantes. Il s’agit bien d’une IP sur le réseau privé; la connexion SSH passera par un jump sur l’hyperviseur.
ℹ️ L’hôte réel pour s’y connecter depuis Ansible sera défini au niveau des variables du groupe.
Créer le vault pour y mettre le mot de passe :
ansible-vault edit hosts/host_vars/bleuet_vm/vault.yml
⚠️ Référencer le mot de passe dans le VW, coffre
paquerette_admin_sys, collectionvm.
Groupe
Dans hosts/10-machines, créer un groupe bleuet qui référence l’hôte :
[bleuet]
bleuet_vm
Ce groupe référencera tous les hôtes de type service qui s’exécuteront sur la VM.
Ajouter une variable de groupe dans hosts/group_vars/bleuet/vars.yml :
ansible_host: bleuet
Ainsi les services savent où s’installer.
⚠️ Par défaut, les VM sont sur un réseau privé et sont accédées par un reverse-proxy. Les services peuvent alors supposer qu’elles ne gèrent pas e.g. les terminaisons TLS. Dans le cas contraire, on ajoutera la variable suivante :
behind_reverse_proxy: false
Dans hosts/50-servers, modifier le groupe dX_vms, X étant le numéro donné à l’hyperviseur. Exemple :
d3_vms:
children:
bleuet:
[...]
En d’autres termes, tous les hôtes du groupe bleuet (services + la VM) bénéficient des variables du groupe d3_vms.
Ajouter l’hôte de la VM au groupe proxmox_dX. Exemple :
proxmox_d3:
hosts:
bleuet_vm:
Création de la VM
Prérequis
Sur l’hyperviseur, vérifier que proxmoxer est au moins en version 2 et installé globalement.
sudo pip3 install --break-system-packages 'proxmoxer>=2.0.0' --upgrade
Création
Lancer le playbook de création de VM en limitant à l’hôte de la VM.
ansible-playbook playbook/vm/create.yml --limit bleuet_vm
À la fin, le playbook affiche le vmid de la VM. L’ajouter dans les variables du groupe. Exemple :
vmid: 122
Cela permet notamment à tous les services du groupe de créer leur disque et de l’attacher à la VM. Attendre le démarrage et confirmer que la connexion SSH fonctionne avec la commande :
# IP et jump dans la configuration SSH de la tower
ssh bleuet
Configuration de la VM
Cette étape installe notamment le pare-feu en autorisant seulement SSH, ZRAM (compression de la RAM), reaction (actions par matching des logs), Rustic (backups), l’agent Zabbix (métriques) et des paquets libres.
La liste des paquets à installer peut être étendue avant configuration dans les variables de l’hôte, par exemple :
dependencies = {{ dependencies + additionnal_packages }}
additionnal_packages:
- sl
Lancer le playbook de configuration :
ansible-playbook playbooks/vm/configure.yml --limit bleuet_vm
Ajouter Des informations supplémentaires dans zabbix
Ex : listes des mails en erreur dans sympa
Sur l’hote
- Créer un fichier sur l’hote dans
/etc/zabbix/zabbix_agent2.d/MON_EXPORTER.confavec la syntaxe suivante :
UserParameter=NOM.PARAMETRE, COMMANDE_À_LANCER
# ex :
# UserParameter=sympa.error, psql -c 'select * from
logs_table;'
- Relancer le service :
systemctl restart zabbix_agent.service
Sur l’interface web
- Aller dans le menu collecte de données->Hotes
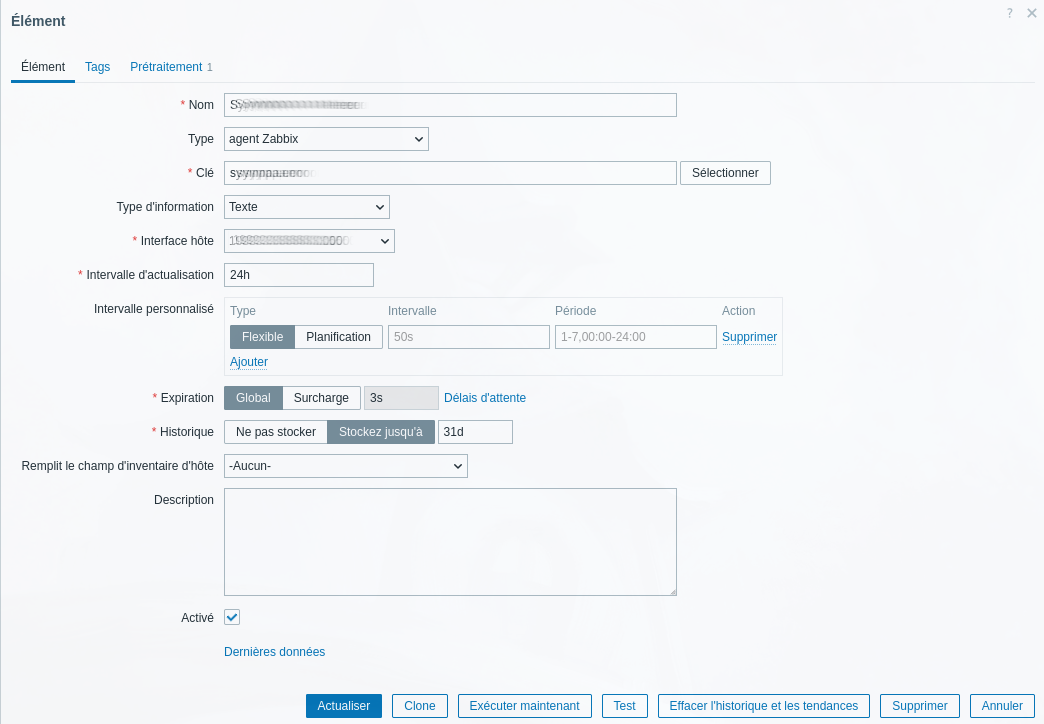
- cliquer sur Éléments puis Créer un Élément
Créer une alerte
Aller dans déclencheur
Créer un déclencheur et chercher l’élément déclencheur (ex: sympa : liste en erreur).
Les déclencheurs se font sur des valeurs numériques. Il faut donc créer une valeur dérivées numérique avec par exemple un jsonpath length pour compter des éléments
Diverse procédures et mémos pour des opérations sur l’adminsys
Installer une nouvelle instance d’un service
Un petit utilitaire (écrit en 🦀™) interactif permet de générer automatiquement les fichier de configuration au bon endroit.
Si le service est correctement configuré dans le fichier add-instance/config.toml, les bonne variables seront automatiquement demandées.
Pour le lancer il suffit de de lancer add-instance.
Lancer un playbook
Il existe un petit helper bash avec autocompletion :
playbook action service id_service [options]
# génère :
ansible-playbook playbook/action/service.yml -l id_service [options]
# ex :
playbook upgrade mattermost mt_tchat_paquerette --skip-tags toto
# génère :
ansible-playbook playbook/install/mattermost.yml -l mt_tchat_paquerette --skip-tags toto
Restaurer des fichiers avec Rustic
- Créer un dossier pour monter temporairement la sauvegarde
- Monter le backup
- dans un nouveau terminal
- naviguer dans les snapshots et copier les fichiers vers la destination
- remettre les droits des fichier copiés
- dans le cas de nextcloud, relancer un scan
- stopper le montage
mkdir /mnt/rustic
mount rustic -P APPLICATION_ID mount /mnt/rustic
# nouveau terminal
cd /mnt/rustic/\[MACHINE\]/\[rustic\ -\ APPLICATION_ID\]/
cp MES_FICHIERS DESTINATION
chown -R APPLICATIION_ID:APPLICATION_ID/www-data DESTINATION
# pour les groupfolder de nextcloud
sudo -u APPLICATION_ID php occ groupfolders:scan --all
# pour les fichier d'un utilisateur
sudo -u APPLICATION_ID php occ files:scan UTILISATEUR
Nextcloud
Ici on liste les trucs et astuces pour Nextcloud
Vider la corbeille des dossiers de groupe
cd <data_nextcloud>
sudo -u www-data php occ groupfolders:trashbin:cleanu
Convertir une base Mysql en Postgres
Attention Il faut être au minimum en version 21.
- Supprimer la base Postgres existante si elle existe
sudo su postgres
psql
drop database MABASE;
- Re-créer la base avec le bon utilisateur
CREATE DATABASE MABASE OWNER MONUSER ENCODING 'UTF8';
GRANT CREATE ON SCHEMA public TO MONUSER;
- Lancer la conversion via l’outil de Nextcloud
occ
sudo -u www-data php7.4 occ db:convert-type --all-apps --password="MOTDEPASSEBASEPG" pgsql nc_USER_usr 127.0.0.1 nc_DATABASE_db
Mise à jour hors ansible.
- lancer la demande de mise à jour via l’interface.
- Appliquer la mise à jour.
- Terminer la mise à jour en ligne de commande avec
sudo -u www-data php occ upgrade
Troubleshooting
Les partages ont disparus
C’est vraissemblablement un problème de rescan des fichiers qui a créé des nouveaux identifiants et n’a pas mis à jour la table ${PREFIX}share. On peut solutionner ce problème en mettant à jour la table avec la commande suivante :
PREFIX="oc_" update ${PREFIX}share set item_source=t.fileid, file_source=t.fileid from (select distinct on (c.fileid) c.fileid as origin, d.path, d.fileid from ${PREFIX}filecache as d right join (select a.path, a.fileid from ${PREFIX}filecache as a right join ${PREFIX}share as b on a.fileid=b.file_source) as c on c.path = d.path order by c.fileid,d.fileid desc) t where ${PREFIX}share.file_source = t.origin;
D’autres commandes disponible :
update oc_share c set file_source=b.fileid, item_source=b.fileid from old_filecache as a left join oc_filecache as b on a.path=b.path where a.fileid=file_source;
# récupérer le chemin complet des fichier partagés
select a.path from oc_filecache as a right join oc_share as b on a.fileid=b.file_source;
# récupérer le dernier Id pour un path donné :
select fileid, path from oc_filecache where path = 'PATH' order by fileid desc;
# recupérer les ancien id par rapport aux nouveaux
select distinct on (c.fileid) c.fileid as origin, d.path, d.fileid from oc_filecache as d right join (select a.path, a.fileid from oc_filecache as a right join oc_share as b on a.fileid=b.file_source limit 10) as c on c.path = d.path order by c.fileid,d.fileid desc;
Édition bloqué dans l’application Forms
Les logs Nextcloud de l’instance retournent
SQLSTATE[42703]: Undefined column: 7 ERROR: column \"locked_by\" of relation \"oc_forms_v2_forms\" does not exist\nLINE 1: UPDATE \"oc_forms_v2_forms\" SET \"locked_by\" = $1, \"locked_unt
Les logs Postgres :
ERROR: column "locked_by" of relation "oc_forms_v2_forms" does not exist at character 32
STATEMENT: UPDATE "oc_forms_v2_forms" SET "locked_by" = $1, "locked_until" = $2, "title" = $3, "last_updated" = $4 WHERE "id" = $5
Pour corriger, il faut ajouter les deux colonnes manquantes locked_by et locked_until
ALTER TABLE oc_forms_v2_forms ADD COLUMN locked_by varchar;
ALTER TABLE oc_forms_v2_forms ADD COLUMN locked_until integer;
Migrer à partir de S3
La procédure utilise le repo présent ici : https://git.paquerette.eu/paquerette/public/nextcloud-S3-local-S3-migration.git
- importer la base de donnée dans l’instance
- cloner le repo dans le dossier
/var/www/APPLICATION_ID - changer les droits à
application_id:www-data - installer
composeret la dépendanceaws/aws-sdk-phpdans le dossiernextcloud-S3-local-S3-migration
sudo -u APPLICATION_ID -- composer require aws/aws-sdk-php
- spécifier
APPLICATION_IDdans le fichiers3tolocal-postgres.php - modifier le fichier
config.phppour ajouter les options liée à S3
'objectstore' => [
'class' => '\\OC\\Files\\ObjectStore\\S3',
'arguments' => [
'bucket' => 'NOM_DU_BUCKET',
'hostname' => 'URL_DE_S3',
'region' => 'us',
'key' => 'MA_CLE',
'secret' => 'MON_SUPER_SECRET',
'use_path_style' => true,
],
],
- monter un volume dans le dossier
/mnt/nextcloud/APPLICATION_ID_bkpavec suffisament d’espace pour récupérer toutes les données - lancer la commande `sudo -u APPLICATION_ID nextcloud-S3-local-S3-migration/
Mattermost
Avant Upgrade
- https://docs.mattermost.com/upgrade/important-upgrade-notes.html
Ligne de commande mmctl
Supprimer une Équipe
- Faire une sauvegarde du fichier
config.json - Activer la configuration expérimental
EnableAPITeamDeletiondefalseàtrue - Redémarrer le service
Se connecter avec le compte admin :
sudo -u mt_tchat_opteos ./bin/mmctl --config ./config/config.json auth login https://chat-opteos.paquerette.eu
Supprimer l’équipe concerné :
sudo -u mt_tchat_opteos ./bin/mmctl --config ./config/config.json auth login https://chat-opteos.paquerette.eu
Migrer depuis RocketChat
Les information sont dans le README du dépot
import de la base de données de rocketchat dans mongo
mongorestore --gzip --archive=2024-04-16T03\:23\:15Z_rs0.dump.gz
Exporter les données au bon format.
Il existe un projet (mattermost-etl-rocketchat pour extraire d’une base de donnée RocketChat les données et les mettre au format mattermost
Troobleshooting
le projet ne supporte que l’export de fichier depuis le filesystem ou gridFS, pas S3. À voir s’il ne faut pas le migrer.
Utilisation du repo filestore-migrator
Ce repo permet de migrer d’un stockage vers un autre via le fichier de conf suivant :
database:
connectionString: "mongodb://localhost:27017/rockethat?directConnection=true&authSource=admin"
database: "rocketchat"
source:
type: "AmazonS3"
AmazonS3:
endpoint: "hot-objects.liiib.re"
bucket: "chat-opteos-fr"
accessId: "ACCESS_ID"
accessKey: "ACCESS_KEY"
region: ""
useSSL: true
destination:
type: FileSystem
FileSystem:
location: "./files"
skipErrors: true
## Modification du projet
Attention, le projet à 2 ans et n'a pas forcément été largement testé, il y a donc des modifications à faire :
### Avant l'export
#### L'objet `user` ne doit pas avoir de `auth_data` si `auth_services` est nul
ajouter dans le fichier `lib/rocketchat/users.js`
if (user.auth_service == “”) { delete user.auth_data }
#### les `username` doivent être lowercase
ajouter dans le fichier `lib/rocketchat/users.js`
```diff
- result.username,
+ result.username.toLowerCase(),
!! TODO !!! remplacer dans les messages et directs channels aussi
ou à postériori
# changer les username
sed -i 's/"username":"\(.*\)","first/"username":"\L\1","first/g' data.jsonl
# changer dans les message
sed -i 's/"members":\["\(.*\)"\]\}\}/"members":\["\L\1"\]\}\}/g' test.jsonl
# et là
sed -i 's/"user":"\(.*\)","create/"user":"\L\1"create/g' data2.jsonl
sed -i 's/members":\["\(.*\)"\],"user/members":\["\L\1"\],"user/g' data2.jsonl
sed -i 's/"user":"\(.*\)","create/"user":"\L\1","create/g' data2.jsonl
un Header de canal ne peut contenir plus de 1024 caractères
ajouter dans le fichier lib/rocketchat/channls.js
- result.topic,
+ result.topic.substring(0,1024)
Après l’export
Un canal ne doit pas commencer par un -
sed -i 's/"-/"0/g' data.jsonl
Les images de profil ne fonctionnent pas, on les supprime
sed -i 's#,"profile_image":".*"##g'
Mettre le dossier d’upload au bon endroit ou changer le chemin :
sed -i 's#./files#/tmp/rocketchat/files#g' data.jsonl
Un user a plusieurs channels de temps en temps
TODO
Importer dans Mattermost
- Bien penser à réhausser la limite d’utilisateurs par équipe
Mattermost est capable de faire des import bulk. Pour ça, il faut activer le mode local executer les commandes suivantes :
sudo -u USER_MATTERMOST ./mmctl import upload --local ARCHIVE.ZIP
# Upload session successfully created, ID: 3jbgyxie9ir1iydf43xgc6gq6a
# récupérer l'ID
sudo -u USER_MATTERMOST ./mmctl import --local process "ID_data.zip"
# Vérifier que tout se passe bien
sudo -u mt_tchat_test_paq ./mmctl import job show --local
Procédure depuis un dump mongo
(spécifique) Récupérér de dump chez indyhosters
- installer le client mc de minio.
- configurer un alias de connection :
mc alias set NOM_ALIAS https://cold-objects.liiib.re ACCESS_KEY SECRET_KEY
- copier le dump sur la machine
mc cp NOM_ALIAS/opteos-fr-dumps/mongodb/NOM_DU_DUMP.dump.gz .
Importer le dump dans mongo
mongorestore mongorestore --archive="NOM_DU_DUMP.dump.gz" --gzip
Créer un utilisateur
#mongosh
db.createUser(
{
user: "etl_user",
pwd: passwordPrompt(), // or cleartext password
roles: [ { role: "read", db: "rocketchat" },]
}
)
Jouer avec la base de données :
Récupérer l’id d’une équipe
select id from teams where name='NAME' ;
Récupérer les canaux d’une équipe
select id from channels where teamid='ID' ;
Récupérer l’id d’un utilisateurs
select id from users where username='USERNAME';
Sélectionner les posts d’un utilisateur dans une équipe
select * from posts where userid='USERID' and channelid in (select id from channels where teamid='TEAMID');
Changer l’utilisateur des messages dans une équipe
update posts set userid='NEW_USERID' where userid='OLD_USER_ID' and channelid in (select id from channels where teamid='TEAM_ID');
Focalboard
Restauration d’un board après suppression
Connexion à la base de donnée concerné
su - postgres
psql
\c MABASE
Récupération de l’ID du board et le numéro (temps ?) de suppression (delete_at)
SELECT id, title, delete_at FROM focalboard_boards_history WHERE delete_at > 0;
Re-création du board
INSERT INTO focalboard_boards SELECT * FROM focalboard_boards_history WHERE id = 'BOARD_ID' AND delete_at > 0;
UPDATE focalboard_boards SET delete_at = 0 WHERE id = 'MON_ID';
Restauration des cartes avec leur données
UPDATE focalboard_blocks_history SET channel_id = 0 WHERE board_id = 'BOARD_ID' AND delete_at > TEMPS_SUPPRESSION;
INSERT INTO focalboard_blocks SELECT * FROM focalboard_blocks_history WHERE board_id = 'BOARD_ID' AND delete_at > TEMPS_SUPPRESSION;
UPDATE focalboard_blocks SET delete_at = 0 WHERE board_id = 'BOARD_ID' AND delete_at > TEMPS_SUPPRESSION;
BigBlueButton
Installation et mise à jour
Version 3.0 :
wget -qO- https://raw.githubusercontent.com/bigbluebutton/bbb-install/v3.0.x-release/bbb-install.sh | bash -s -- -w -v jammy-300 -s bbb-test.paquerette.eu -e postmaster@paquerette.eu -g
-winstallation de ‘the uncomplicated firewall’ (UFW) pour restreindre l’accès aux ports 22, 80, et 443, et la plage de port UDP 16384-32768.-v jammy-300installation de la dernière version 3.0-sle nom de l’hôte server (par exemplebbb.paquerette.eu)-eajouter une adresse mail pour la validation du certificat Let’s Encrypt.-gInstaller Greenlight version 3
Customisation/Configuration Pâquerette
Ajouter la génération des enregistrements vidéos
https://docs.bigbluebutton.org/administration/customize/#enable-generating-mp4-h264-video-output
Ajouter un bouton télécharger direct à l’interface
- aller dans le conteneur
docker exec -it greenlight-v3 /bin/bash - ajouter dans le fichier
/usr/src/app/app/javascript/components/recordings/RecordingRow.jsxentre<td className="border-start-0">et{adminTableles lignes suivantes
<a download="enregistrement.m4v" href={`/playback/video/${recording.record_id}/video-0.m4v`}>
<svg xmlns="http://www.w3.org/2000/svg" fill="currentColor" stroke-width="1.5" class="hi-s text-muted" viewBox="0 0 512 512">
<path d="M288 32c0-17.7-14.3-32-32-32s-32 14.3-32 32l0 242.7-73.4-73.4c-12.5-12.5-32.8-12.5-45.3 0s-12.5 32.8 0 45.3l128 128c12.5 12.5 32.8 12.5 45.3 0l128-128c12.5-12.5 12.5-32.8 0-45.3s-32.8-12.5-45.3 0L288 274.7 288 32zM64 352c-35.3 0-64 28.7-64 64l0 32c0 35.3 28.7 64 64 64l384 0c35.3 0 64-28.7 64-64l0-32c0-35.3-28.7-64-64-64l-101.5 0-45.3 45.3c-25 25-65.5 25-90.5 0L165.5 352 64 352zm368 56a24 24 0 1 1 0 48 24 24 0 1 1 0-48z"/>
</svg>
</a>
Présentation cachée par défaut
la configuration est disponible ici : /usr/share/meteor/bundle/programs/server/assets/app/config/settings.yml
L’option s’appelle userdata-bbb_hide_presentation_on_join
Version 3.0
Désormais la configuration s’effectue dans le fichier /etc/bigbluebutton/bbb-html5.yml
public:
layout:
hidePresentationOnJoin: true
Puis on recharge la configuration
bbb-conf --restart
Détails de la session caché pour tous
Dans le fichier /etc/bigbluebutton/bbb-html5.yml
public:
layout:
showSessionDetailsOnJoin: false
Puis on recharge la configuration
bbb-conf --restart
Création d’un url sur mesure pour salle
Il est possible de changer l’url pour une de son choix en ligne de commande dans BBB. cf issue
greenlight v2
docker exec -it greenlight-v2 bash
bundle exec rails c
Room.find_by(uid: "CURRENT_ROOM_ID").update_attribute(:uid, "NEW_CUSTOM_ID")
Greenlight v3
docker exec -it greenlight-v3 bash
bundle exec rails c
Room.find_by(friendly_id: "CURRENT_ROOM_ID").update_attribute(:friendly_id, "NEW_CUSTOM_ID")
Changer l’adresse d’un utilisateur
docker exec -it postgres /usr/local/bin/psql -U postgres greenlight-v3-production
SELECT id, email FROM users WHERE email = 'MONADRESSE@paquerette.eu';
UPDATE users
SET email = 'NOUVEAUMAIL@paquerette.eu'
WHERE id = '31193b1a-bfee-400f-b180-086d04def4c9';
SELECT id, email FROM users WHERE id = '31193b1a-bfee-400f-b180-086d04def4c9';
Synchroniser les enregistrements BBB avec Greenlight
docker exec -it greenlight-v3 bash
bundle exec rails server_recordings_sync
Migration Greenlight V2 vers Greenlight V3
Les migrations ne fonctionnaient pas car le “provider” nommé “greenlight” n’était pas présent dans le programme de migration.
Nous avons donc modifié le code avec les éléments suivant
--- migrations.rake.old 2024-06-06 16:40:12.502232922 +0200
+++ migrations.rake 2024-06-06 16:53:53.872925118 +0200
@@ -68,7 +68,7 @@
.where.not(roles: { name: COMMON[:filtered_user_roles] }, deleted: true)
.find_each(start: start, finish: stop, batch_size: COMMON[:batch_size]) do |u|
role_name = infer_role_name(u.role.name)
- params = { user: { name: u.name, email: u.email, external_id: u.social_uid, language: u.language, role: role_name } }
+ params = { user: { name: u.name, email: u.email, external_id: u.social_uid, language: u.language, role: role_name, provider: 'greenlight' } }
response = Net::HTTP.post(uri('users'), payload(params), COMMON[:headers])
@@ -81,7 +81,7 @@
puts red "Unable to migrate User:"
puts yellow "UID: #{u.uid}"
puts yellow "Name: #{params[:user][:name]}"
- puts red "Errors: #{JSON.parse(response.body.to_s)['errors']}"
+ puts red "Errors: #{JSON.parse(response.body.to_s)}"
has_encountred_issue = 1 # At least one of the migrations failed.
end
end
@@ -133,7 +133,8 @@
last_session: r.last_session&.to_datetime,
owner_email: r.owner.email,
room_settings: room_settings,
- shared_users_emails: shared_users_emails } }
+ shared_users_emails: shared_users_emails,
+ provider: 'greenlight' } }
response = Net::HTTP.post(uri('rooms'), payload(params), COMMON[:headers])
@@ -188,7 +189,7 @@
glRequireAuthentication: infer_room_config_value(setting.get_value('Room Authentication'))
}.compact
- params = { settings: { site_settings: site_settings, room_configurations: room_configurations } }
+ params = { settings: { site_settings: site_settings, room_configurations: room_configurations, provider: 'greenlight' } }
response = Net::HTTP.post(uri('settings'), payload(params), COMMON[:headers])
@@ -197,7 +198,7 @@
puts green "Successfully migrated Settings"
else
puts red "Unable to migrate Settings"
- puts red "Errors: #{JSON.parse(response.body.to_s)['errors']}"
+ puts red "Errors: #{response}"
has_encountred_issue = 1 # At least one of the migrations failed.
end
cd greenlight/
- Migration des rôles (pas important dans le cas de Pâquerette car pas très utilisé)
docker exec -it greenlight-v2 bundle exec rake migrations:roles
* Migration des comptes
docker exec -it greenlight-v2 bundle exec rake migrations:users
* Migration des salles
docker exec -it greenlight-v2 bundle exec rake migrations:rooms
Problèmes rencontré.
-
Parfois, le passage des mises à jours système et/ou les mises à jours des conteneurs créer des erreurs de connexion audio (surtout des micro) avec des erreurs 1006 Il faut donc repasser le script d’installation.
-
GreenLight V3:
Il y avait de nombreux bug d’affichage qui sont résolu actuellement avec la version 3.0.4 Un bug d’upload était encore présent du à la configuration Nginx (peut-être lié à la version 2 de Greenlight). Il faut retirer la fin de la configuration comme expliqué ici : https://github.com/bigbluebutton/greenlight/issues/4810
Dans le fichier /usr/share/bigbluebutton/nginx/greenlight.nginx (ce qui est lié à rails).
Non support de l’ipv6
Par défaut, BBB ne supporte que l’ipv4. pour ajouter l’ipv6, il faut modifier le fichier /etc/haproxy/haproxy.cfg
frontend nginx_or_turn
+ bind :::443 v4v6 ssl crt /etc/haproxy/certbundle.pem ssl-min-ver TLSv1.2 alpn h2,http/1.1,stun.turn +
- bind *:443 ssl crt /etc/haproxy/certbundle.pem ssl-min-ver TLSv1.2 alpn h2,http/1.1,stun.turn -
mode tcp
Migrations de serveur vers une nouvelle version
On fait en sorte que le serveur de destination soit avec les mêmes configurations que le serveur actuel.
1- Arrêt du service GreenLight sur le serveur actuel et sur le serveur de destination
cd /root/greenlight-v3
docker compose down
2- Sauvegarde de la configuration du service existant sur le serveur de destination
cp -rf /root/greenlight-v3 /root/greenlight-v3.old
2- Transfert du service GreenLight à partir du serveur actuel
rsync -av /root/greenlight-v3 root@SERVEURORIGINE:/root/greenlight-v3
3- Transfert des vidéos depuis le serveur actuel
rsync -av /var/bigbluebutton/published/ root@SERVEURORIGINE:/var/bigbluebutton/published/
rsync -av /var/bigbluebutton/unpublished/ root@SERVEURORIGINE:/var/bigbluebutton/unpublished/
rsync -av /var/bigbluebutton/recording/raw/ root@SERVEURORIGINE:/var/bigbluebutton/recording/raw/
Récupérer un enregistrement dans les sauvegardes :
- Monter les sauvegardes sur le serveur :
rustic -P bigbluebutton mount /mnt/
- Trouver l’enregistrement à partir de l’identififiant
ls /mnt/[bigbluebutton.paquerette.eu]/[rustic - bigbluebutton]/${DATE_SAUVEGARDE-*}/var/bigbluebutton/published/*/$IDENTIFIANT
- Copier le fichier
/mnt/[bigbluebutton.paquerette.eu]/[rustic - bigbluebutton]/${DATE_SAUVEGARDE-*}/var/bigbluebutton/published/video/$IDENTIFIANT/video-0.m4vdans un autre repertoire. - Mettre à disposition la vidéo.
YesWiki
Requetes SQL
Sélectionner les fiches d’un formulaire
select * from yeswiki_pages where tag in (select resource from yeswiki_triples where value = 'fiche_bazar') and latest = 'Y' and JSON_VALUE(body, '$.id_typeannonce') = $NUM$;
Sélectionner toutes les fiches bazar non géolocalisées
select * from yeswiki_pages where tag in (select resource from yeswiki_triples where value = 'fiche_bazar') and latest = 'Y' and JSON_VALUE(body, '$.id_typeannonce') = $NUM$ and JSON_EXISTS(body, '$.geolocation') = false;
Supprimer les fiches avec certains champs vides
delete from yeswiki_pages where tag in (select resource from yeswiki_triples where value = 'fiche_bazar') and latest = 'Y' and JSON_VALUE(body, '$.id_typeannonce') = $NUM$ and JSON_EXTRACT(body, '$.CHAMP') = '' and JSON_EXTRACT(body, '$.CHAMP') = "" and JSON_EXTRACT(body, "$.CHAMP") = "";
Mettre à jour un nom de champ
update yeswiki_pages set body=JSON_INSERT(body, "$.NOUVEAU NOM",JSON_VALUE(body, "$.ANCIEN_NOM")) where tag in (select resource from yeswiki_triples where value = 'fiche_bazar') and latest = 'Y' and JSON_VALUE(body, '$.id_typeannonce') = $NUM$ and JSON_EXISTS(body, "$.ANCIEN_NOM");
Supprimer les espaces en trop
update yeswiki_pages set body = regexp_replace(body, ', "', ',"') where tag in (select resource from yeswiki_triples where value = 'fiche_bazar') and JSON_VALUE(body, '$.id_typeannonce') = 2 and body REGEXP ', "';
update yeswiki_pages set body = regexp_replace(body, ': "', ':"') where tag in (select resource from yeswiki_triples where value = 'fiche_bazar') and JSON_VALUE(body, '$.id_typeannonce') = 2 and body REGEXP ': "';
Formulaires
Cacher les champs vides d’un formulaire :
<script>var non_empty_cor = Array.prototype.filter.call( document.getElementsByClassName('field-text'),function (el) { return el.dataset.id.match('correspondant[0-4]$'); },); for (el of non_empty_cor) { document.getElementById(el.dataset.id).hidden=false; } </script>
Importer du json depuis un csv :
- lancer le one liner suivant pour faire un json :
cat ficher.csv | python -c 'import csv, json, sys; print(json.dumps([dict(r) for r in csv.DictReader(sys.stdin)]))' >> fiches_actions.json
- doubler les
\d’échapement. - mettre des | au lieu des “.
- importer dans une table mariadb :
load data infile '/tmp/fiches_actions.csv' into table tmp fields terminated by ',' enclosed by '|';
Gitlab
Mise à jour
C’est le paquet Gitlab qui est installé.
sudo apt update
sudo apt upgrade
Vérification
1 - Régénération de la configuration
sudo gitlab-ctl reconfigure
2 - Redémarrage du service
sudo gitlab-ctl restart
Gitlab Runner
Pour avoir la construction d’un conteneur dans un conteneur, il faut passer les étapes suivantes
Ajouter dans le fichier ``
services:
gitlab-runner:
image: 'gitlab/gitlab-runner:latest'
container_name: runner-docker-dind
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- ./config:/etc/gitlab-runner
restart: unless-stopped
On ajoute le dossier de configuration
mkdir config
Démarrage du conteneur
docker-compose up -d
On enregistre le nouveau runner auprès de Gitlab. Des instructions vont être demandés.
docker-compose exec gitlab-runner gitlab-runner register
Un fichier est ajouté dans le dossier de configuration config/config.toml (on modifie la lign volumes)
volumes = ["/cache", "/var/run/docker.sock:/var/run/docker.sock"]
Gitlab Registry
TODO
OnlyOffice
Ajouter de nouvelles polices
Dans un conteneur existant :
- copier les polices :
docker compose cp font.ttf onlyoffice:/usr/share/font - executer le script documentserver-generate-allfonts.sh :
docker compose exec onlyoffice documentserver-generate-allfonts.sh
Dans la construction du conteneur :
- Ajouter les fichiers dans le dossier
./fonts/fonts
Wordpress
Dolibarr
Vaultwarden
Sources :
- Officiel : https://github.com/dani-garcia/vaultwarden
- Documentation : https://github.com/dani-garcia/vaultwarden/wiki
- Dépôt de paquets Debian : https://apt.crunchy.run/vaultwarden/
Configuration
Le fichier de configuration est /etc/vaultwarden/vaultwarden.env
#Configuration des dossiers
DATA_FOLDER=DESTINATION
TMP_FOLDER=DESTINATIONtmp
WEB_VAULT_FOLDER=/var/www/DESTINATION
#Base de donnée
DATABASE_URL=postgresql://MONUSER:MOTDEPASSE@localhost:5432/MABASE
#Domaine
DOMAIN=https://domain.tld
#Sécurité et affichage
SIGNUPS_ALLOWED=false
SIGNUPS_VERIFY=true
INVITATIONS_ALLOWED=true
INVITATION_ORG_NAME=Mon Jolie Coffre
INVITATION_EXPIRATION_HOURS=120
EMERGENCY_ACCESS_ALLOWED=true
EMAIL_CHANGE_ALLOWED=true
IP_HEADER=X-Real-IP
# Configuration des logs
EXTENDED_LOGGING=true
LOG_TIMESTAMP_FORMAT="%Y-%m-%d %H:%M:%S.%3f"
LOG_FILE=/var/log/vaultwarden/vaultwarden.log
LOG_LEVEL=info
# Mails
SMTP_HOST=mail.chatons.fr
SMTP_FROM=joliecoffre@chatons.fr
SMTP_FROM_NAME=vw_paquerette
SMTP_USERNAME=postmaster@chatons.fr
SMTP_PASSWORD=MOTDEPASSE
SMTP_TIMEOUT=15
SMTP_SECURITY=starttls
SMTP_PORT=587
# Accès au web service
ROCKET_ADDRESS=127.0.0.1
ROCKET_PORT=4567
Installation
On suit la documentation disponible sur le site du dépôt : https://apt.crunchy.run/vaultwarden/
1- Ajout de la clé du dépôt
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://apt.crunchy.run/keys/signing-key.gpg | sudo tee /etc/apt/keyrings/apt-crunchy-run.gpg > /dev/null
2- Ajout des instructions du dépôts
sudo tee /etc/apt/sources.list.d/vaultwarden.sources > /dev/null <<EOF
Types: deb
URIs: https://apt.crunchy.run/vaultwarden
Suites: trixie
Components: main
Signed-By: /etc/apt/keyrings/apt-crunchy-run.gpg
EOF
3- Installation des paquets
apt update
apt install vaultwarden vaultwarden-web-vault
Humhub
Grist
Connexion avec Nextcloud
Installation du plugin OIDC Identity Provider
Sur l’intance Nextcloud, on installe l’application OIDC Identity Provider : https://apps.nextcloud.com/apps/oidc
Disponible aussi sur le dépôt : https://github.com/H2CK/oidc
Documentation du plugin : https://github.com/H2CK/oidc/wiki/User-Documentation
Configuration
On ajoute un client avec les informations suivantes :
- Nom : Grist
- URIs de redirection : https://grist.[MONSITE]/oauth2/callback
Configuration du service via Docker
Dans le fichier grist.env :
GRIST_OIDC_IDP_ISSUER=https://nextcloud.[MONSITE]/index.php/.well-known/openid-configuration
GRIST_OIDC_SP_HOST=https://grist.[MONSITE]
GRIST_OIDC_SCOPES=openid profile email
GRIST_OIDC_IDP_CLIENT_ID=[Identifiant fourni par l'application Nextcloud]
GRIST_OIDC_IDP_CLIENT_SECRET=[Secret fourni par l'application Nextcloud]
Mosparo
Mosparo est un système d’aide à la détection de robot de spam : https://mosparo.io/
Installation
Nous avons un rôle Ansible qui est basé sur l’installation “normal” documenté ici: https://documentation.mosparo.io/docs/installation/install/normal
Intégration
Wordpress
Intégration Wordpress : https://github.com/mosparo/wordpress-plugin
Pour utiliser le plugin, il faut suivre les instructions suivantes:
- Se connecter sur l’administration du site Wordpress
- Dans la partie plugin, cliquer sur Install
- Chercher “mosparo Integration”
- Installer le plugin
- Activer le plugin
- Aller dans les paramètres du plugin et ajouter les éléments lié au projet
- Activer les modules nécessaire
- Si vous avez un fomulaire de contact, vous pouvez ajouter un champ pour mosparo
Attention ! Le plugin est compatibles avec les modules suivant: Account, Comments, ContactForm7, EverestForms, Formidable, GravityForms, NinjaForms, WPForms
Custom
Intégration custom : https://documentation.mosparo.io/docs/integration/custom
Utilisation
Sur la page d’accueil, on peut gérer les projets Sur un projet, on peut gérer les membres de celui-ci, les status et les utilisations des tockens
Dans la partie administration, nous pouvons gérer les utilisateurs, les mises à jours et les configurations lié au système
coturn
L’instance coturn de Paquerette est accessible à l’adresse turn.paquerette.eu aux ports 3478 et 5349.
La version en clair se préfixe traditionnellement avec stun: et la version chiffrée avec stuns:. Les ports peuvent être utilisés indifféremment.
Il y a un seul secret partagé entre toutes les applications qui l’utilisent (dans le VW : Infra/coturn). Ce sont ensuite les applications qui sécurisent les échanges en distribuant des identifiants uniques temporaires à leurs utilisateur·ices (voir rôle).
Si l’application cliente n’a qu’une interface « utilisateur/mot de passe », rentrer le secret à la place du mot de passe et laisser l’utilisateur vide.
Alpine
Trucs et astuces pour Alpine
Ajouter un service au redémarrage
rc-update add MONSERVICE default
Mettre à jour la base de paquet
apk update
Mettre à jour les paquets
apk upgrade
Faire une montée de version
- Vérification de la version
cat /etc/alpine-release - Vérification des dépôts
cat /etc/apk/repositories - Modification de la version des dépôts (Attention ici pour la version 3.19 à 3.20)
sed -e 's/3.19/3.20/g' -i /etc/apk/repositories - On vérifie les modifications
cat /etc/apk/repositories - On met à jour la base des dépôts
apk update - Avant la mise à jour, on met à jour le gestionnaire de paquets
apk add --upgrade apk-tools - Mise à jour
apk upgrade --available
L'option --available permet de forcer la mise à jour des paquets même s'ils sont dans la même version.
Cela est nécessaire pour réinstaller les paquets compilés avec la bonne version de musl. (sinon on peut avoir quelques problèmes)
- Redémarrer
reboot
Configurer le temps
setup-timezone -z Europe/Paris
Fail2ban
Source : https://wiki.alpinelinux.org/wiki/Fail2ban
Install
apk add fail2ban
Activer le service fail2ban
rc-update add fail2ban
Démarrer le service fail2ban et la création de la configuration:
rc-service fail2ban start
Lister les service actif
rc-status
Configuration
Configuration files are located at /etc/fail2ban
cat /etc/fail2ban/jail.d/alpine-ssh.conf
[sshd]
enabled = true
filter = alpine-sshd[mode=aggressive]
port = ssh
logpath = /var/log/messages
maxretry = 2
vi /etc/fail2ban/jail.d/alpine-ssh.conf
[sshd]
enabled = true
filter = alpine-sshd
port = ssh
logpath = /var/log/messages
maxretry = 2
[sshd-ddos]
enabled = true
filter = alpine-sshd-ddos
port = ssh
logpath = /var/log/messages
maxretry = 2
[sshd-key]
enabled = true
filter = alpine-sshd-key
port = ssh
logpath = /var/log/messages
maxretry = 2
vi /etc/fail2ban/filter.d/alpine-sshd-key.conf
# Fail2Ban filter for openssh for Alpine
#
# Filtering login attempts with PasswordAuthentication No in sshd_config.
#
[INCLUDES]
# Read common prefixes. If any customizations available -- read them from
# common.local
before = common.conf
[Definition]
_daemon = sshd
failregex = (Connection closed by|Disconnected from) authenticating user .* <HOST> port \d* \[preauth\]
ignoreregex =
[Init]
# "maxlines" is number of log lines to buffer for multi-line regex searches
maxlines = 10
rc-service fail2ban restart
How to test new filters
fail2ban-regex /var/log/messages alpine-sshd-key.conf
Unban ip
fail2ban-client set sshd unbanip BannedIP
Docker
Installation
apk add docker docker-compose
Dans un conteneur LXC (sur proxmox par exemple), ajouter ceci :
lxc.apparmor.profile: unconfined
lxc.cap.drop:
Zabbix
Installation de l’agent
apk add zabbix-agent2 zabbix-agent2-plugin-alpine
Configuration spécifique
Le dépôt contient toutes les instructions pour la mise en place de la configuration
Wireguard
Attention, il faut bien activer l’IP Forwarding sur notre système. Et le rendre persistant.
Activation :
echo 1 > /proc/sys/net/ipv4/ip_forward
Pour le rendre persistant, ajouter au sysctl :
net.ipv4.ip_forward=1
Debian
Installation des paquets
apt install wireguard wireguard-tools
Génération des clés
wg genkey | sudo tee /etc/wireguard/wg-private.key | wg pubkey | sudo tee /etc/wireguard/wg-public.key
Affichage des clé pour l’ajout aux configurations
cat /etc/wireguard/wg-private.key
cat /etc/wireguard/wg-public.key
Configuration
vim /etc/wireguard/wg0.conf
[Interface]
Address = 172.16.16.16/24
SaveConfig = true
PostUp = iptables -A FORWARD -i wg0 -j ACCEPT; iptables -t nat -A POSTROUTING -o enp7s0 -j MASQUERADE
PostDown = iptables -D FORWARD -i wg0 -j ACCEPT; iptables -t nat -D POSTROUTING -o enp7s0 -j MASQUERADE
ListenPort = 51234
PrivateKey = SNkHh4mupzBty5EYZG3cA6YliWqxNE4dS0NFYvt+b3A=
[Peer]
PublicKey = 23SOICm8uhCcga/KANTufWfCkJyvRgMJEnH3CeA18Xc=
AllowedIPs = 172.16.16.26/32, 192.168.100.0/24
Endpoint = 31.14.71.72:51234
Faire la même configuration sur la machine en face en adaptant la configuration des adresses IP.
Monter la nouvelle interface wg0 et l’activer
wg-quick up wg0
wg show wg0
systemctl enable wg-quick@wg0.service
systemctl start wg-quick@wg0.service
systemctl status wg-quick@wg0.service
Alpine LXC
Installation
apk add wireguard-tools wireguard-tools-wg wireguard-tools-wg-quick
Génération des clés de chiffrement
wg genkey | tee /etc/wireguard/wg-private.key | wg pubkey > /etc/wireguard/wg-public.key
Configuration
vim /etc/wireguard/wg0.conf
[Interface]
Address = 172.16.16.26/24
SaveConfig = true
PostUp = iptables -A FORWARD -i wg0 -j ACCEPT; iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
PostDown = iptables -D FORWARD -i wg0 -j ACCEPT; iptables -t nat -D POSTROUTING -o eth0 -j MASQUERADE
ListenPort = 51234
PrivateKey = gA5oSQ68uCfOOH3SmADlYN1i92UsOz5wVF1HelXe0mY=
[Peer]
PublicKey = vEwwRdzT9a5sMM1VXrX3szR6cTBDgmTmcZD9MssGYAs=
AllowedIPs = 172.16.16.16/32, 10.0.0.0/24
Endpoint = 168.119.239.115:51234
Démarrage automatique
- Ajout du lien pour le démarrage
ln -s /etc/init.d/wg-quick /etc/init.d/wg-quick.wg0 - Il est possible de démarrer le service :
rc-service wg-quick.wg0 start
Sympa
Sympa n’est pas géré par Ansible, on fait ici une liste à compléter au fil de l’eau des opérations utiles, notamment pour les nouveaux admins.
📜 Pour le troubleshooting mail, voir la documentation dédiée.
Une très bonne introduction, explicitant des éléments difficiles à inférer de la documentation officielle, est consultable sur ce PDF.
Généralités
L’ensemble des listes Sympa est géré via une mono-instance hébergée sur origan.
- Utilisateur
sympa; - Une BDD
sympavia l’utilisateursympa; - Dossier de configuration
/etc/sympa;
Pour un aperçu de la hiérarchie et des différents fichiers de configuration, voir la documentation officielle.
💡 Certains fichiers n’existent par liste, par exemple
edit_list.conf. Dans ce cas, créer le fichier avec l’ownershipsympa:sympa.
Sympa est contrôlé par systemd à travers deux services principaux :
sympapour le backend;wwsympapour le serveur web.
Configuration générale
Elle est dans /etc/sympa/sympa/sympa.conf.
(Note) On Debian 8 (jessie) or earlier, /etc/sympa/sympa.conf is used. On Debian 9 (stretch) or later, /etc/sympa/sympa.conf may also be used, though /etc/sympa/sympa/sympa.conf is used by default. (source)
💡 Certains paramètres semblent sortir de nulle part : ils ne sont pas définis dans un fichier de configuration actif, mais existent tout de même. L’astuce utilisée par les mainteneurs du paquet Sympa pour contourner l’absence de fusion des fichiers de configuration est d’utiliser un script Perl pour assigner les valeurs par défaut : voir
/usr/share/sympa/lib/Sympa/Config/Schema.pm.
Ajout d’un·e admin à un domaine
En plus de la configuration générale de l’instance, chaque domaine a une configuration spécifique dans /etc/sympa/<domaine>.
Le fichier robot.conf permet d’appliquer des paramètres “haut niveau”, e.g. nom de domaine, signatures cryptographiques, etc.
La clé listmaster configure les administrateur·ices des listes du domaine, sous le format suivant :
listmaster nom@tld,nom2@tld2,[...]
⚠️ Chez Paquerette, certains domaines n’ont pas de compte admin partagé : il faut créer un compte personnel et le rajouter à cette liste.
Une fois que la modification est faite, il faut redémarrer Sympa et son serveur mail :
systemctl restart sympa
systemctl restart wwsympa
Modifier les privilèges de paramétrage des listes
Sympa permet de configurer finement quel rôle peut éditer quel paramètre depuis l’interface web via le fichier edit_list.conf.
Un défaut est fourni avec le paquet Debian (/usr/share/sympa/default/edit_list.conf). En l’absence de configuration pour l’instance ou pour une liste en particulier, c’est à ce fichier que Sympa se réfère.
⚠️ Le fonctionnement de la configuration est hiérarchique mais il n’y a pas de fusion. Sympa s’arrête au premier fichier trouvé; il faut donc recopier tous les paramètres par défaut que l’on ne souhaite pas changer.
Cette configuration est conçue par exclusion. En effet les lignes suivantes :
default privileged_owner write
default owner write
default editor read
default listmaster write
indiquent par exemple que les propriétaires des listes peuvent éditer tous les paramètres qui ne sont pas explicitement reconfigurés.
À titre d’exemple, max_size est configuré comme tel :
max_size owner,privileged_owner hidden
En conséquence, les administrateur·ices et éditeurs peuvent lire et écrire la taille maximale des messages, mais les propriétaires des listes ne voient même pas ce champ.
Déléguer la vérification de la taille maximum à Sympa
Contexte
Par défaut, Sympa est configuré avec max_size == 5242880 (voir configuration générale), c’est-à-dire 5Mo. En cas de dépassement de la taille, Sympa envoie un hard bounce à l’émetteur.
Mais il faut encore que le mail arrive jusqu’à Sympa. En effet, s’il est envoyé depuis un MUA autre que Sympa, il passe d’abord par Postfix (voir ce schéma de fonctionnement moins général mais qui s’applique ici).
On peut vérifier la configuration de Postfix comme suit :
$ postconf -d | grep message_size_limit
message_size_limit = 10240000
C’est le défaut, soit 10Mo.
Quel impact sur le comportement ?
Le comportement n’est donc pas homogène entre Sympa et Postfix.
Si la taille du message est comprise entre 5 et 10Mo, c’est Sympa qui rejette le message et renvoie par mail une “raison” lisible par les humains, par exemple :
## Message trop gros
Ceci est une réponse automatique du robot de listes Sympa.
Problème de diffusion de votre message pour la liste `quentin-test@<DOMAIN>` :
Votre message n'a pas pu être envoyé parce que sa taille (8302 ko) était supérieure à la taille maximum de message autorisée pour cette liste (5120 ko).
Si la taille du message est supérieure à 10Mo, c’est Postfix qui rejette le message (ça pourrait être via un code d’erreur SMTP qui sera immédiatement affiché par le MUA, mais c’est par un hard-bounce). Le mail est moins lisible, par exemple :
## Undelivered Mail Returned to Sender
I'm sorry to have to inform you that your message could not
be delivered to one or more recipients. It's attached below.
[...]
The mail system
<quentin-test@<DOMAIN>.fr>: message size 21525473 exceeds size
limit 10240000 of server listes.paquerette.eu[148.251.158.205]
On retrouve bien les deux limites, dans les deux cas.
Laisser Sympa s’occuper de la taille des mails
La solution consiste à (virtuellement) désactiver la limite de taille côté Postfix. Peu d’effets indésirables sont à prévoir; en effet :
- Dans tous les cas, les mails sont entièrement téléversés avant d’être rejetés (pas d’ajout de surface de DoS);
- À travers l’interface Sympa, un mail trop volumineux serait rejeté directement;
- L’intégralité des mails sont présumés transiter par Sympa;
- Dans l’éventualité d’une fuite, les MTA intermédiaires rejetteraient alors le mail, mais il est peu vraisemblable que cela soit un motif de mise sur liste noire (les spammeurs n’utilisent pas les gros fichiers).
La valeur de message_size_limit est limitée à LONG_MAX, soit au minimum 2Go sur les systèmes 32 bits.
Considérant qu’un humain n’a probablement aucune bonne raison d’essayer d’envoyer une pièce jointe de plus de 100Mo, ou que le cas est suffisamment rare pour essuyer un message d’erreur plus cryptique, on ajoute la ligne suivante dans /etc/postfix/main.cf1 :
message_size_limit = 104857600
Enfin, vérifier que la configuration est correcte et la recharger :
postconf
postfix reload
-
Le calcul est fait sur cette ressource en considérant les puissances de 2 (*“kilo” is 1024). ↩
Discourse
Installation
une fois le discourse installé, il faut encore modifier l’adresse d’expedition des emails.
Vars
discourse utilise les variables suivante
À définir dans le host_vars
- application_domain
- application_admin_password
- application_db_password
Définies dans le groupe du vps du service
Définies dans le role
- instance_id : {{ inventory_hostname }}
- discourse_version : 3.2.2
Définies globalement
- smtp_host
- smtp_port
- smtp_password
- smtp_secure
- smtp_auth_type
- smtp_usr
Nextcloud
Faire des modifications de nextcloud qui se conservent d’une mise à jour à l’autre
Le script d’upgrade intègre une étape qui permet de lancer des commandes arbitraires en temps que l’utilisateur de l’instance à la fin de la mise à jour dans le dossier de l’instance.
Pour ça, il faut créer la variable customizations et indiquer la ligne de commande correspondante dans un tableau.
Ex:
customizations:
[
# augementation du rate limit de création de lien de partage
"sed -i 's/#\\[UserRateLimit(limit: 20, period: 600)\\]/#\\[UserRateLimit(limit: 100, period: 600)\\]/g' apps/files_sharing/lib/Controller/ShareAPIController.php
]
Vars
nextcloud utilise les variables suivante
À définir dans le host_vars
- application_domain
- admin_password
Définies dans le groupe du vps du service
- trusted_proxy
Définies dans le role
- data_dir : /mnt/nextcloud/{{ application_id }}
- application_db_name : {{ application_id }}_db
- application_db_user : {{ application_id}}_usr
- maintenance_window_start : 2
- application_id : {{ inventory_hostname }}
- php_version : 8.2
- pg_version : 15
- packages :
- application: nextcloud
- version: “28.0.10”
- download_url: “https://download.nextcloud.com/server/releases/nextcloud-{{ version }}.tar.bz2”
- application_checksum
Définies globalement
- smtp_host
- smtp_port
- smtp_name
- smtp_password
- smtp_secure
- smtp_auth_type
- smtp_usr
- smtp_mode
- smtp_domain
Listmonk
Installation
une fois le discourse installé, il faut encore modifier l’adresse d’expedition des emails.
Vars
Listmonk utilise les variables suivante
À définir dans le host_vars
- application_domain
- application_admin_password
- application_db_password
Définies dans le groupe du vps du service
Définies dans le role
- instance_id : {{ inventory_hostname }}
- listmonk_version : v4.1.0
Définies globalement
- smtp_host
- smtp_port
- smtp_password
- smtp_secure
- smtp_auth_type
- smtp_usr
Dolibarr
Vars
dolibarr utilise les variables suivante
À définir dans le host_vars
- application_domain
Définies dans le groupe du vps du service
- mysql_root_password
Définies dans le role
- application_db_name : {{ application_id }}_db
- application_db_user : {{ application_id}}_usr
- application_id : {{ inventory_hostname }}
- php_version : 8.3
- packages :
- application: dolibarr
- version: “1.17.2”
- download_url:
- application_checksum
Définies globalement
- smtp_host
- smtp_port
- smtp_name
- smtp_password
- smtp_secure
- smtp_auth_type
- smtp_usr
- smtp_mode
- smtp_domain
YesWiki
Vars
yeswiki utilise les variables suivante
À définir dans le host_vars
- application_domain
Définies dans le groupe du vps du service
- mysql_root_password
Définies dans le role
- application_db_name : {{ application_id }}_db
- application_db_user : {{ application_id}}_usr
- application_id : {{ inventory_hostname }}
- php_version : 8.2
- packages :
- application: yeswiki
- version: “4.5.0”
- download_url:
- application_checksum
Définies globalement
- smtp_host
- smtp_port
- smtp_name
- smtp_password
- smtp_secure
- smtp_auth_type
- smtp_usr
- smtp_mode
- smtp_domain
Humhub
Vars
humhub utilise les variables suivante
À définir dans le host_vars
- application_domain
Définies dans le groupe du vps du service
- mysql_root_password
Définies dans le role
- application_db_name : {{ application_id }}_db
- application_db_user : {{ application_id}}_usr
- application_id : {{ inventory_hostname }}
- php_version : 8.3
- packages :
- application: humhub
- version: “1.17.2”
- download_url:
- application_checksum
Définies globalement
- smtp_host
- smtp_port
- smtp_name
- smtp_password
- smtp_secure
- smtp_auth_type
- smtp_usr
- smtp_mode
- smtp_domain
Paheko
Vars
À définir dans le host_vars
- application_domain
Défninies dans le groupe du vps du service
Définies dans le role
- php_version : 8.2
- packages :
- application : paheko
- version : “1.3.8”
- download_url : “https://fossil.kd2.org/paheko/uv/paheko-{{ version }}.tar.gz”
- application_checksum :
Mattermost
Vars
Mattermost utilise les variables suivante
À définir dans le host_vars
- application_domain
- application_port
- admin_password
- application_db_password
Définies dans le groupe du vps du service
- behind_reverse_proxy
- vmid
Définies dans le role
- application_db_name : {{ application_id }}_db
- application_db_user : {{ application_id}}_usr
- application_id : {{ inventory_hostname }}
- pg_version : 15
- application: mattermost
- version: “10.4.2”
- download_url: “https://releases.mattermost.com/{{ app_version }}/mattermost-{{ app_version }}-linux-amd64.tar.gz”
- application_checksum
Définies globalement
- smtp_host
- smtp_port
- smtp_name
- smtp_password
- smtp_secure
- smtp_auth_type
- smtp_usr
- smtp_mode
- smtp_domain
coturn
Configuration
Voir coturn.conf.
Utilisateurs
coturn permet de définir des utilisateurs dans une base de données. C’est ce qui était fait à l’origine dans ce rôle, avec un utilisateur par application.
Mais en fait, pour que ça fonctionne, il faudrait un utilisateur par utilisateur réel. Nexcloud Talk, par exemple, explique que pour un utilisateur global à l’application :
As the global TURN credentials are sent to each participant in a call (registered and anonymous), everybody could (ab-)use the credentials to create other connections through the TURN server from other services.
Au final, l’approche est d’utiliser un secret global côté serveur d’application, qui lui se charge de distribuer (en gros) des identifiants temporaires. Cette approche n’est pas normalisée, c’est un draft IETF, mais largement utilisée car implémentée dans coturn qui fait référence et bien adaptée à WebRTC/ICE.
To retrieve a new set of credentials, the client [e.g. Nexcloud Talk] makes a HTTP GET request, specifying TURN as the service to allocate credentials for, and optionally specifying a user id parameter. The purpose of the user id parameter is to simplify debugging on the TURN server, as well as provide the ability to control the number of credentials handed out for a specific user, if desired. The TURN credentials and their lifetime are returned as JSON, along with URIs that indicate how to connect to the server using the TURN protocol.
Firewall
Il doit ouvrir en UDP la plage de ports 49152 → 65535 (c’est sur cette plage qu’un port aléatoire servira pour faire relai entre les clients, en cas de dernier recours), et en TCP 3478 et 5349.
Tests
Utiliser Trickle ICE, proposé par le projet WebRTC.
On testera la version “en clair” (le flux est chiffré dans tous les cas) et la version TLS. Les deux ports marchent pour les deux types, mais par convention on utilisera turns:<domain>:5349 pour indiquer, au moins aux humains, le chiffrement.
Laisser l’utilisateur vide et mettre le secret global en mot de passe (voir vault de l’hôte).
Il faut ensuite cliquer sur Gather candidates et attendre que le test termine.
Tester ensuite sur une application, par exemple Nextcloud Talk.
Backups
Il y a bien une base de données mais elle est pleine d’utilisateurs « jetables », ça ne vaut a priori pas le coup.
Flarum
Vars
Flarum utilise les variables suivante
À définir dans le host_vars
- application_domain
Définies dans le groupe du vps du service
- mysql_root_password
Définies dans le role
- application_db_name : {{ application_id }}_db
- application_db_user : {{ application_id}}_usr
- application_id : {{ inventory_hostname }}
- php_version : 8.2
- packages :
- application: yeswiki
- version: “4.5.0”
- download_url:
- application_checksum
Définies globalement
- smtp_host
- smtp_port
- smtp_name
- smtp_password
- smtp_secure
- smtp_auth_type
- smtp_usr
- smtp_mode
- smtp_domain
grist
Inventaire
download_archive
Introduction
Gestion centralisée des fichiers et de leurs signatures, à utiliser pour tous les fichiers qui seraient normalement téléchargés sur différentes machines.
L’idée est de ne télécharger le fichier qu’une fois (sur la tower), tout en vérifiant sa signature, et en offrant un cache persistant.
Ce rôle cherche le fichier demandé dans le dépôt situé sur la tower et le télécharge si nécessaire. Aucune hypothèse n’est faite sur la nature du téléchargement; le fichier est sauvegardé tel quel.
Il expose ensuite la variable application_file_location qui contient le chemin du fichier sur la tower.
Dans les deux cas, la signature est vérifiée et le rôle échoue en cas de corruption. Les signatures supportées sont le hash sha256 et minisig.
Variables génériques
Le rôle s’attend à recevoir les variables suivantes :
application: nom de l’application (arbitraire mais doit être unique);version: version de l’application (idem);download_url: URL de téléchargement du fichier;variant:[sha256|minisig](défaut :sha256)
sha256
Variable spécifique :
application_checksum: hashsha256à confronter au hash du fichier téléchargé.
minisign
Variables spécifiques :
download_url_sig: URL du fichier.minisigà télécharger.key: clé publique associée à la signature.
⚠️ Si le nom du fichier à télécharger est
file, le nom du fichier de signature doit êtrefile.minisig.
⚠️ La signature
inlinen’est pas supportée (sera implémentée selon les besoins).
💡 Le système de signature s’appelle
minisign, mais l’extension de signature est.minisig.
Exemple d’utilisation
- name: Download and verify reaction package
# Vérifie le cache et la signature, (re-)télécharge si besoin
import_role:
name: download_archive
vars:
application: reaction
version: "{{ reaction_version }}"
# À préciser obligatoirement pour `minisign`
variant: minisign
download_url: "https://static.ppom.me/reaction/releases/{{ reaction_version }}/reaction_{{ reaction_version_deb }}_amd64.deb"
download_url_sig: "https://static.ppom.me/reaction/releases/{{ reaction_version }}/reaction_{{ reaction_version_deb }}_amd64.deb.minisig"
# La clé est normalement donnée par l'auteur·ice
key: RWSpLTPfbvllNqRrXUgZzM7mFjLUA7PQioAItz80ag8uU4A2wtoT2DzX
- name: Fetch reaction package from tower
copy:
# Le playbook est supposé lancé depuis la tower, ainsi
# on peut utiliser le chemin retourné, qui est de fait local
src: "{{ application_file_location }}"
# Chemin sur l'hôte distant
dest: "/tmp/reaction.deb"
# Cas où le fichier existe déjà à l'identique : permet
# de pousser le cache jusqu'au bout
force: false
mode: "0640"
Instance prod
Un role qui doit être déclenché à l’installation, la désinstallation et la mise à jour d’un service. Il permet de consigner l’état actuel de l’infrastructure dans un dépot git.
Ce role est fortement couplé avec notre infrastructure. présentement, les valeurs sont marquée en dur dans le role et pas stockée dans des variables
Vars
Définies dans le host_vars
- application_domain
Définies dans le groupe du vps du service
- ansible_host
Définies dans le groupe du service
- application
Définies dans le role qui l’appelle
- operation
Rustic
Vars
rustic utilise les variables suivante
À définir dans le host_vars
- rustic_password
À définir dans le role
- rustic_backup_sources
- rustic_backup_before
- rustic_backup_after
Définies dans le role
- application: rustic
- version: “0.9.5”
- download_url: “https://github.com/rustic-rs/rustic/releases/download/v{{ version }}/rustic-v{{ version }}}}-x86_64-unknown-linux-gnu.tar.gz”
- application_checksum
- application_id
Définies globalement
- rustic_endpoint
- rustic_user
- rustic_key_location
Create VM
Particularités
Le playbook create_vm.yml ne marche pas encore très bien.
Une fois le playbook correctement passé, aller dans proxmox et démarrer la VM.
La première fois, on obtient un kernel panic et la deuxième fois, ça marche.
Lancer ensuite le playbook configure_vm.yml
Configurer l’ipv6 sur d2 :
Il faut aller sur le firewall et rajouter l’ip virtuelle dans interfaces -> IPs virtuelles -> paramètres
Vars
create VM utilise les variables suivante
À définir dans le host_vars
- ansible_host:
- ip:
- vm_admin_password: “{{ vault_admin_password }}”
Définies dans le groupe de la vm
- pve_api_user: “paquerette@pam”
- pve_api_token_id: “{{ vault_pve_api_token_id }}”
- pve_api_token_secret: “{{ vault_pve_api_token_secret }}”
- pve_api_host: “d2.paquerette.eu”
- pve_node: “d2”
- pve_api_node: “{{ pve_node }}”
- pve_template_name: “debian12-cloudinit”
- pve_storage_name: “data”
- ansible_host: d2
Définies dans le role
- pve_vm_name: “{{ inventory_hostname | regex_replace(‘_vm’,‘’) }}”
- pve_cores: 2
- pve_memory: 2048
- pve_min_memory: “{{ (pve_memory | int / 2) | int }}”
- node_ip_config: “ip=192.168.0.{{ ip }}/24,gw=192.168.0.1,ip6=2a01:4f8:262:52ed:10{{ ip }}::1/80,gw6=2a01:4f8:262:52ed:1002::1”
- dependencies: [“curl”, “git”, “vim”, “nano”, “wget”, “rsync”]
- reaction_version: “v2.0.0-rc1”
reaction
Pas grand chose à savoir “extra-reaction”.
Usuellement il suffit de modifier le numéro de version dans les variables et de répercuter les éventuels breaking changes. Pour l’instant, la rétrocompatibilité est assurée sur la version 2, donc il n’y a qu’une seule procédure d’installation et de mise à jour.
Services
Clients
Machines
Router un service non-HTTP
⚠️ On ne traite pas le cas OPNsense.
Contexte
Certains services (comme coturn) ne sont pas des services web et ne sont donc pas gérables par Caddy (qui est un reverse-proxy HTTP uniquement).
On suppose ce service installé sur une machine virtuelle sans accès direct à Internet.
Avec des approximations pour simplifier, la configuration est la suivante :
┌────────────────────────┐
│ Caddy │
│ │
┌─────────────────┐ │ eth0 ─┐ eth1 ──┐ │
│ Hyperviseur │ │ │ │ │
│ │ └─────────┼────────────┼─┘ ┌─────────────────┐
│ │ │ │ │ VM service │
┌────────────┐ │ │ │ │ │ │
│ │ │ │ vmbr0 │ │ vmbr10 │ │
│ Internet │ │ │ ┌──┼──────┐ ┌──┼───────┐ │ │
│ ┼─────┼─────► eno1 ────┼──────────┼► ▼ │ │ ▼ ◄──┼──────┼───── eth0 │
│ │ │ │ │ │ │ ▲ │ │ │
└────────────┘ │ │ └─────────┘ └────┼─────┘ │ │
│ vmbr10 ────┼────────────────────────────┘ │ │
│ │ │ │
└─────────────────┘ └─────────────────┘
L’hyperviseur a l’accès à Internet et route l’IPv4 et des blocs IPv6 vers le bridge vmbr0 à destination de Caddy, qui ensuite communiquera avec les VM de services via le bridge vmbr10, qui lui est interne.
On suppose ici que notre application écoute sur le port 3478 sur la VM, et qu’on veut pouvoir y accéder depuis l’Internet.
Prérequis
Vérifier que le port 3478 est ouvert sur l’hyperviseur et la VM.
Vérifier que le domaine a bien un enregistrement A qui pointe vers l’hyperviseur (pas de CNAME à cause de l’IPv6, voir plus bas).
Cas de l’IPv4
Puisque l’hyperviseur et la VM sont sur le bridge vmbr10, il suffit de NATer le port 3478 depuis l’hyperviseur.
iptables -t nat -A PREROUTING -d <IP SERVICE>/32 -p tcp --dport 3478 -j DNAT --to-destination <IP VM eth0>
Pour que le changement soit persistent au démarrage, le rajouter dans /etc/network/interfaces.
Cas de l’IPv6
Le NAT n’existe pas en IPv6. Côté hébergeur, il est coutume de router une IPv4 et un bloc /64 IPv6 vers les machines louées. Une IP de ce bloc doit être attribuée directement à une interface de la VM.
Choisir l’IPv6
En général, un sous-bloc est déjà routé sur vmbr0:
# Depuis l'hyperviseur $ ip -6 route 2a01:4f8:2220:235b:1000::/80 dev vmbr0 metric 1024 pref medium 2a01:4f8:2220:235b:1001::/80 dev vmbr0 metric 1024 pref medium [...]
⚠️ Il faut nécessairement être sur
vmbr0pour que la VM ait accès l’IP publique de l’hyperviseur (sa passerelle).
En général toujours, les premières IP de ce bloc sont utilisées (par l’hyperviseur, Caddy). Pour être sûr on peut par rapport prendre les derniers chiffres de l’IPv4 du service pour choisir la nouvelle IPv6. Par exemple, si l’IP termine par .7.12, on pourra choisir:
2a01:4f8:2220:235b:1000::712
Créer un enregistrement AAAA qui pointe vers cette IP.
Attribuer l’IPv6
En général, les VM n’ont pas d’IPv6. Il faut arriver à la situation suivante :
┌────────────────────────┐
│ Caddy │
│ │
┌─────────────────┐ │ eth0 ─┐ eth1 ──┐ │
│ Hyperviseur │ │ │ │ │
│ │ └─────────┼────────────┼─┘ ┌─────────────────┐
│ │ │ │ │ VM service │
┌────────────┐ │ │ │ │ │ │
│ │ │ │ vmbr0 │ │ vmbr10 │ │
│ Internet │ │ │ ┌──┼──────┐ ┌──┼───────┐ │ │
│ ┼─────┼─────► eno1 ────┼──────────┼► ▼ │ │ ▼ ◄──┼──────┼───── eth0 │
│ │ │ │ │ ▲ │ │ ▲ │ │ │
└────────────┘ │ │ └─────┼───┘ └────┼─────┘ │ │
│ vmbr10 ────┼────────────────┼───────────┘ │ eth1 │
│ │ └────────────────────────┼────────┐ │
└─────────────────┘ └────────┼────────┘
│
│
2a01:4f8:2220:235b:1000::712
C’est-à-dire créer une nouvelle interface sur la VM de service, la connecter au bridge “public” (vmbr0), lui attribuer l’IP et renseigner sa passerelle.
L’adresse IPv6 de la passerelle est logiquement portée par vmbr0.
# Sur l'hyperviseur
$ ip -6 a l vmbr0 | grep global
inet6 2a01:4f8:2220:235b::3/128 scope global
Pour créer une interface et la configurer de façon pérenne, on préfèrera passer par l’interface graphique de Proxmox.
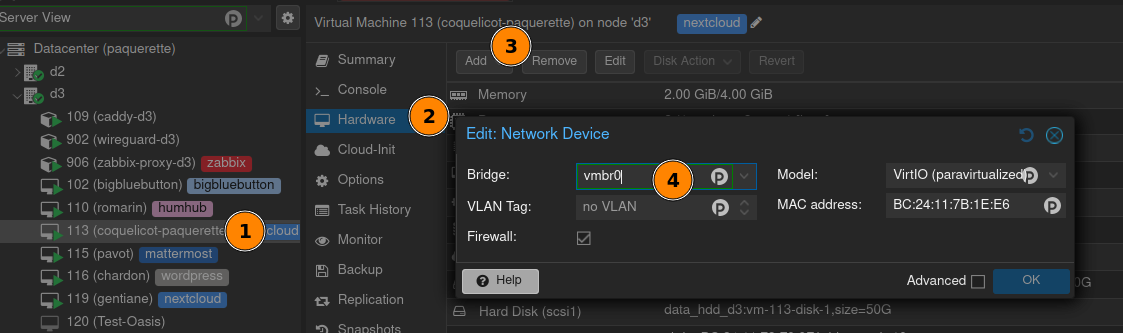
Idem pour la configuration de l’IP de l’interface et la passerelle.
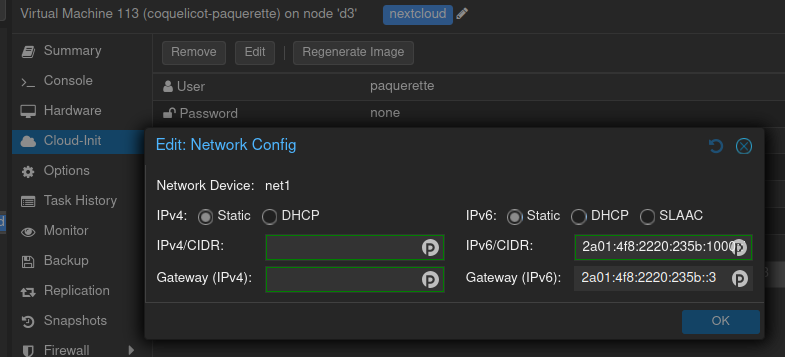
Il faut ensuite redémarrer la machine.
Réparer la route
À ce stade, l’IPv6 n’est parfois pas accessible, bien que la route avec la passerelle existe. C’est parce que la passerelle n’est apparemment pas sur le même bloc que l’IP de la VM. Par exemple sur d3/coquelicot :
# Route de la coquelicot vers la passerelle sur d3 :
default via 2a01:4f8:2220:235b::3 dev eth1 metric 1 pref medium
# IPv6 coquelicot :
2a01:4f8:2220:235b:1000::712/80
L’IP de la passerelle est en effet implicitement sur le /64, ce qui suffit à décourager le routage. Il faudra rajouter l’option onlink sur la route pour expliciter le fait que ces deux machines se trouvent bien à un saut d’écart.
Il faut recréer la route. Dans notre exemple :
ip -6 route delete default via 2a01:4f8:2220:235b::3 dev eth1 metric 1 pref medium
ip -6 route add default via 2a01:4f8:2220:235b::3 dev eth1 onlink
Ce document vise à répertorier le debug des technos du mail, pas à être exhaustif.
Pour les éléments de compréhensions, on pourra se référer à ce document pour le mail et ce document pour SPF/DKIM/DMARC/ARC.
Contexte
origan → /etc/sympa → sympa.conf : défauts qui peuvent être écrasés par X/robot.conf (X = nom de domaine de la mailing)
Là il y a des paramètres DKIM par exemple pour viecoop.lanef.com.
Il y a plusieurs cas :
- mails vers une ML : passage par Sympa puis relai-smtp
- mails vers
viecoop.lanef.comqui n’est pas une mailing liste : envoi vers Galae.
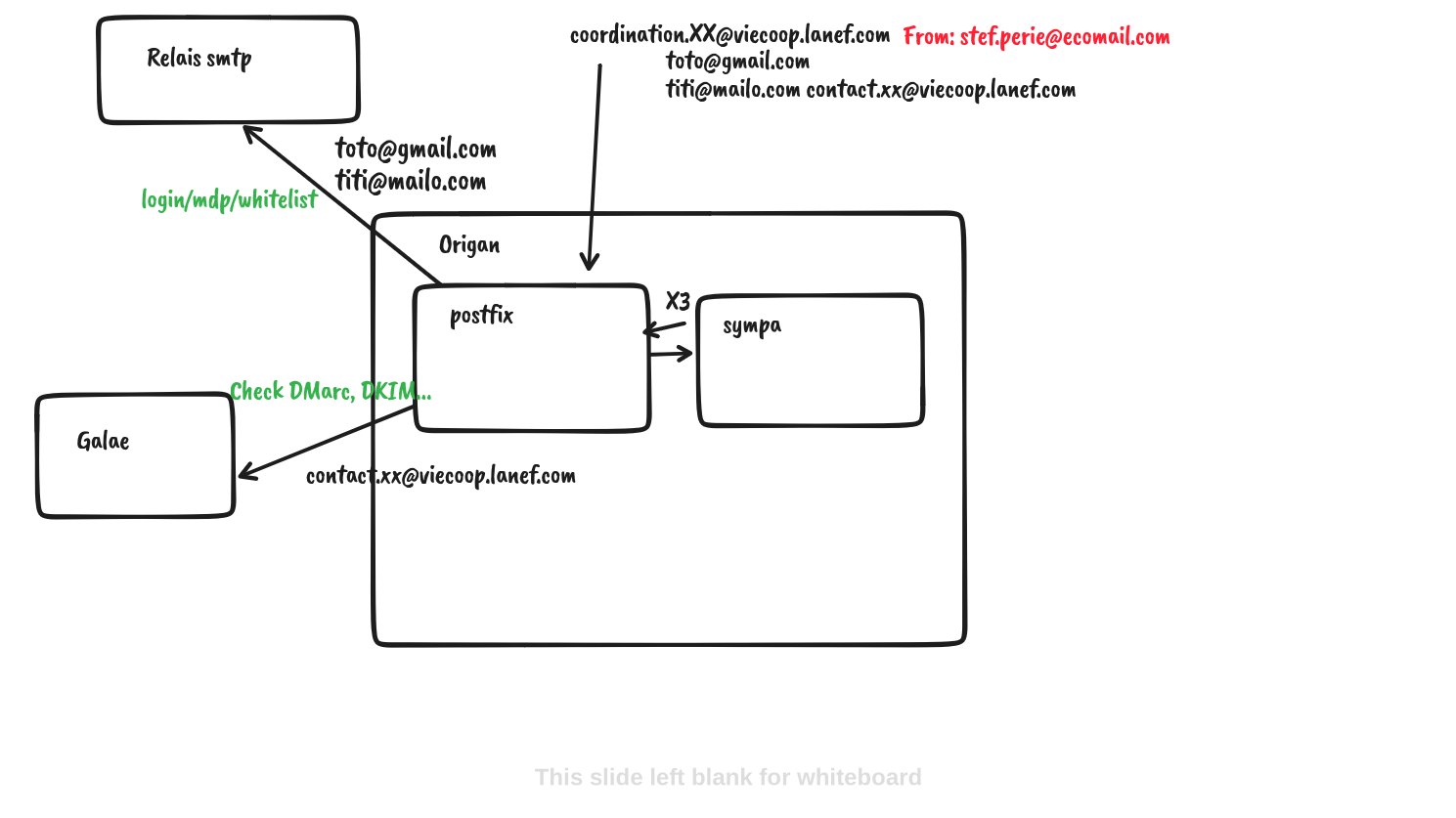
Se posent plusieurs questions autour des méthodes d’authentification des mails.
SPF
En général on fait attention à SPF quand on relaie un message au nom d’un domain qu’on ne contrôle pas; or avec Sympa l’intégralité des mails qui sortent du serveur ont un domaine que l’on contrôle, avec un enregistrement SPF qui nous autorise à émettre pour eux.
Il n’y a donc pas d’intérêt à faire du SRS et il ne devrait pas avoir de soucis.
DKIM
Relai-Smtp, quand il est utilisé, agit comme un serveur de soumission, et signe lui-même les mails avec la clé DKIM configurée.
Pour les domaines pouvant sortir ailleurs, on active DKIM sur Sympa au niveau du domaine.
💡 Relai-Smtp écrase les signatures DKIM de Sympa, donc ce n’est pas un problème s’il y a de l’overlap.
⚠️ Les paramètres ne sont pas homogènes d’une version à l’autre, et configurer DKIM même en le désactivant explicitement l’activera quand même.
DMARC
DMARC, en plus de faire le point sur SPF et DKIM, ne fait que valider l’alignement du domaine entre l’enveloppe, le domaine de la signature et le header.
Peu importe qui émis la signature DKIM, donc, pourvu qu’il ait une clé privée valide.
ARC
ARC peut être activé via Sympa, et de façon plus intéressante dans une future version où il pourra également faire la vérification entrante ARC/DKIM (et sera donc en mesure de construire de construire les headers d’authentification sans un outil tiers).
ARC permet en théorie de détecter les usurpations de façon plus robuste. En effet, il est aujourd’hui admis que rejeter un mail car SPF est cassé n’a aucun sens à cause du forwarding.
Pour autant, ARC retient l’authentification du mail sur toute la chaîne, donc :
- Si SPF est cassé lors de l’envoi du mail, mais forwardé quand même;
- Si la chaîne de headers ARC est valide et les intermédiaires de confiance;
Alors le serveur final peut avoir une grande confiance dans le fait qu’SPF était cassé dès le début, et rejeter le mail.
C’est ce semble faire Galae, intentionnellement ou non (?), cependant les RFC ARC ne recommendent de l’utiliser que lorsque DMARC ne passe pas, par exemple. Or pour nous, DMARC passe notamment via DKIM.
On désactive donc ARC.
Mais ça ne suffit pas car il suffit qu’une seule signature avant nous soit cassée pour que la vérification échoue en bout de chaîne.
On supprime donc l’intégralité des headers ARC avec Postfix.
/etc/postfix/header_checks:
/^ARC-Seal:/ IGNORE
/^ARC-Message-Signature:/ IGNORE
/^ARC-Authentication-Results:/ IGNORE
puis postmap, puis dans main.cf:
smtp_header_checks = regexp:/etc/postfix/header_checks
Ce qui aura pour effet de supprimer les lignes comportant ces headers.
Systemd
Timer systemd
Service
[Unit]
Description= rustic %i service
[Service]
Type=oneshot
ExecStart=/usr/local/bin/rustic --use-profile %i backup --json
StandardOutput=file:/backups/zabbix/%i.json
Timer
[Unit]
Description=Run restic@.service night
[Timer]
OnCalendar=*-*-* 00:00:00
AccuracySec=1us
Persistent=true
RandomizedDelaySec=10800
FixedRandomDelay=true
JournalCtl
Pour regarder l’ensemble des journaux en cours
jounalctl
Pour suivre les journaux en temps réel
journalctl -f
Filtrer par service
journalctl -u crond
Si le 4ème champ n’est pas un service (par exemple les événements sudo), on utilisera -t :
journalctl -t sudo
Filtrer par programme
journalctl /usr/sbin/sshd
Filtrer par niveau de log (ici que les erreurs) :
journalctl -p err
On peut aussi filtrer les logs par date avec –since et –until. Il faut mettre la date au format YYYY-MM-DD HH:MM:SS
journalctl --since "2026-01-10 21:00:00" --until "2026-01-10 22:00:00"
On peut parfois utiliser les dates avec des adverbes de temps (exemple depuis hier)
journalctl --since yesterday
Ou une durée (il y a 15 minutes) :
journalctl --since "15 minutes ago"
Il est possible de visualiser les journaux depuis le boot de la machine :
journalctl -b
Pour le boot d’avant ajouter -2 :
journalctl -b -2
Nginx
Problème rencontrés
upstream sent too big header while reading response header from upstream
Postgres
Se connecter sur le moteur
sudo -u postges psql
Lister les bases
\l
Lister les tables
\dt
ou
\dt *.*
SELECT * FROM information_schema.tables;
Créer un utilisateur
CREATE USER [name] WITH PASSWORD '[password]';
Modifier le mot de passe d’un utilisateur
ALTER USER [name] WITH PASSWORD '[password]';
Créer une base de données
CREATE DATABASE [name]
Taille d’un schema
SELECT pg_size_pretty(sum(pg_relation_size(quote_ident(schemaname) || '.' || quote_ident(tablename)))::bigint) FROM pg_tables WHERE schemaname = 'yourschema';
Redis
se connecter au moteur de base
redis-cli
Informations sur les bases
redis-cli INFO | grep ^db
db0:keys=1500,expires=2
db1:keys=200000,expires=1
db2:keys=350003,expires=1
sed
Mettre une colonne en ligne
%s/$\n/, /g